How Xata works
How Xata works
Xata is a new type of cloud service: it offers an abstraction layer on top of multiple data stores in order to make application development and operations simpler. We call this type of service a Serverless Data Platform. This document explains the internal architecture of the Xata service, which can be useful to build a correct mental model of Xata. It can also be useful if you want to replicate the same architecture for yourself, which would give you some of the benefits of using Xata.
If you just want to build apps and use the Xata serverless service, you do not need to read this document. We’re solving these problems so that you don’t have to.
Xata is a global multi-tenant system, composed of cells, each living in a region. At the high level, one Xata cell implements the following architecture:
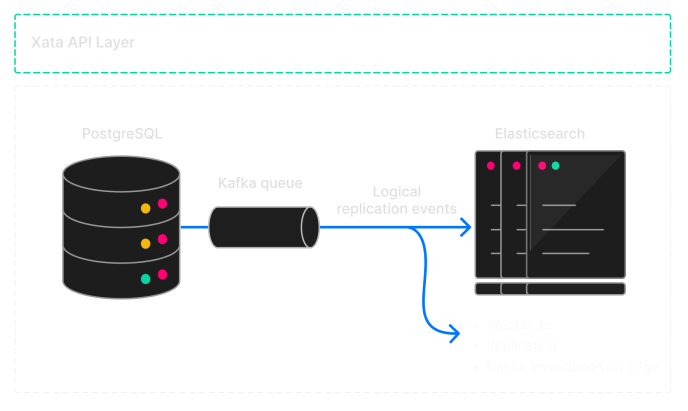
- The data is stored in PostgreSQL, which is considered the source of truth.
- The PostgreSQL logical replication events are written in a Kafka queue, from where they can be read by multiple consumers.
- One of these consumers indexes the data into Elasticsearch.
- The Xata API layer offers a RESTful API offering both the functionality of the relational database (PostgreSQL) with the advanced search and analytics from the search engine/columnar store (Elasticsearch).
- On top of this API, Xata has client SDKs and a web interface.
While the above architecture is a very common one in the industry, it hasn’t been —until now— productized in a service, which means a lot of teams were forced to either implement something similar to the above or live with reduced functionality.
As we’ve seen above, we call the combination of PostgreSQL + Elasticsearch and the associated services a “cell”. The cells are grouped into regions and form our data plane.
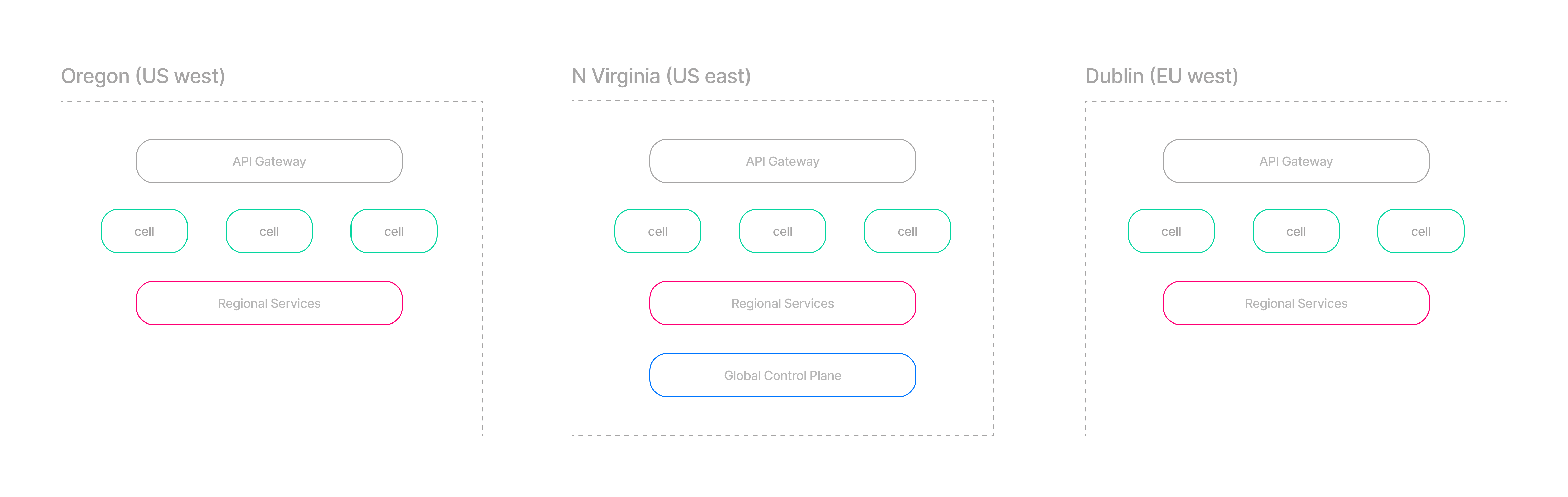
Besides the cells, the regions contain other services:
- An API Gateway service exists in each region and is responsible for routing between cells and enforcing the rate limits.
- Several other supporting regional services, including regional control plane services and a service for running long-running tasks.
- A global control plane layer responsible for maintaining users, workspaces, and API keys.
The control plane information (users, workspaces, API keys) is stored in a single central region and then replicated in near real-time to all other regions. This way, we can offer minimal latencies in each geographical area while still maintaining the convenience of a global service.
Xata has a relational data model, with a strict schema (schemaful) and with support for JSON-like objects. Records are grouped into tables, which are grouped into databases. Xata supports rich column types and relations between tables can be represented via link columns, which are similar to foreign keys.
A record in Xata can look something like this:
{
"name": "John Doe",
"email": "john@example.com",
"age": 42,
"address": "123 Main St, New York",
"labels": ["admin", "user"]
}The above shows a column of type email and an array-like column (labels of type multiple). When this data is stored in PostgreSQL and Elasticsearch, columns are identified by IDs. By using IDs for columns, instead of their user-visible names, we make some migrations simpler and we make it possible, for example, to track a column across branches even if it was renamed.
As a result, the underlying PostgreSQL table might look something like this:
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
_id | text | | not null | | extended | |
_version | integer | | not null | 0 | plain | |
a | text | | | | extended | |
b | text | | | | extended | |
c | bigint | | | | plain | |
d | boolean | | | | plain | |
e | text | | | | extended | |
g | text | | | | extended | |
h | text[] | | | | extended | |
Indexes:
"tbl_cd46p95cefoedabj77gg_a_pkey" PRIMARY KEY, btree (_id)
"tbl_cd46p95cefoedabj77gg_a_replica_id" UNIQUE, btree (_id, _version) REPLICA IDENTITY
"tbl_cd46p95cefoedabj77gg_a_xata_unique_b" UNIQUE CONSTRAINT, btree (b)
Check constraints:
"tbl_cd46p95cefoedabj77gg_a_xata_multiple_length_h" CHECK (octet_length(array_to_string(h, ''::text)) < 65536)
"tbl_cd46p95cefoedabj77gg_a_xata_string_length_a" CHECK (length(a) <= 2048)
"tbl_cd46p95cefoedabj77gg_a_xata_string_length_b" CHECK (length(b) <= 2048)
"tbl_cd46p95cefoedabj77gg_a_xata_string_length_g" CHECK (length(g) <= 2048)
"tbl_cd46p95cefoedabj77gg_a_xata_text_length_e" CHECK (octet_length(e) < 204800)We also rely on PostgreSQL to enforce constraints (unique, not null), data size limitations, and referential integrity for the linked columns. Array types, like multiple, are represented using PostgreSQL array types.
Our data model contains rich types, which refer to data types that allow for more complex and structured data representations that can include a short “string” column (containing a name, or a label) and a “text” column (containing maybe a blog post in Markdown). This means we can have the same defaults for representing and indexing those columns in both PostgreSQL and Elasticsearch.
A database in Xata can have multiple branches, which are first-class citizens in the API. Branches are full logical databases that might or might not exist on the same set of physical instances. When you start a new branch from an existing one, the schema is copied, but the data is not automatically available in the new branch. As you create a development branch from a production branch, you can copy and sanitize parts of the data or initialize the branch with test data.
For each branch, we record the schema history in a list of “commits”. These commits contain operations like “add a column”, “rename a column”, “add a new table”, “delete a table”, and more. We also record which branch is created from which. This history information, together with the fact that each table and column are identified by IDs, allows us to create the correct migration diffs and perform the minimum set of operations required for a migration.
There are multiple benefits to having database branches, which is why lately they are being adopted by multiple database products:
- enable development workflows that match Git workflows, for example having a branch for development, one for staging, one for production, etc.
- enable development previews on platforms like Vercel and Netlify.
- enable standardized workflows for applying schema migrations safely.
The last one is particularly interesting because migrating database schemas is usually easy with small amounts of data, but becomes very painful when dealing with large amounts of data. In the NoSQL wave of DB products, this issue was avoided by going schemaless. However, not having a schema introduces its own class of problems, so lately the pendulum is swinging back toward databases with strict schemas.
One reason why migrations are difficult at scale is that ALTER statements can lock the database table. If an ALTER statement takes an exclusive table lock and it takes, say, one minute to execute, it essentially means one minute of downtime for your application, which is usually unacceptable. In PostgreSQL some ALTER statements are “safe”, meaning that they don’t take an exclusive lock, or if they take a lock they hold it for a very small amount of time. Simple migrations like adding a column or dropping a column are usually safe in PostgreSQL, but if that column has constraints, then the operation might become unsafe.
Because we have control over the data model and because Xata has native concepts of migrations and migration requests, we can ensure that all supported migration types are safe. That’s why we call our migrations zero-downtime migrations. They constrain you in what types of migrations exists, but you can have the confidence that your workflow will keep working at scale.
At the moment the set of migrations supported in Xata is limited to operations that are safely supported by PostgreSQL, but we are growing it to include long-running migrations. For example, if you need to change a column’s type from string to int that requires a costly data migration, and errors can be discovered at execution time. Because we separate the visible schema from the underlying PostgreSQL schema, we can approach it like this:
- add a new
intcolumn with a new internal ID , but don’t expose it in the user schema yet. - start a long-running task that converts the data in batches from
stringtointand write the results to the new column. - for new writes to the table, we write to both the
stringand theintcolumns. - when the long-running task is finished, we can swap the two columns atomically in the user schema.
At any point, the migration can be canceled without a major impact. It is also possible to have the old and the new schema both be active in parallel for some time, simplifying your application upgrade.
It is very useful to get a near-real-time stream with all the changes that are in the database. In database terminology, this is called Change Data Capture. In PostgreSQL, this can be done based on the logical replication functionality, which is available since PostgreSQL 10. By hooking into this functionality, we are receiving an event every time a row is changed in PostgreSQL, regardless what has caused the change. It is somewhat similar to database triggers functionality but with better reliability.
We are using logical replication events today to replicate the data from PostgreSQL into Elasticsearch, and in the near future, we’ll use it to call Webhooks, trigger serverless functions, replication between regions, and more.
One interesting challenge with processing replication events is that it’s generally hard to guarantee exactly-once delivery and the ordering of events. Solutions for delivery in order usually imply a single thread of processing. Instead, we have chosen to use version numbers for the records, which are incremented every time a record is updated or deleted. On the consumer side, these versions can be used to both identify duplicate events and to know in which order they are safe to apply.
The version field for a record is stored in a special column, which is exposed in the Xata API because it is also useful for optimistic concurrency control.
Another typical challenge with logical replication is that the number of events created can become quite large and overwhelm the PostgreSQL replication slot. For example, imagine running a statement UPDATE foo with no WHERE condition executed against a table with millions of rows. PostgreSQL executes that in a single transaction at the end of which all the rows in the table have been changed and need to be passed through the replication slot. Issues like this make it hard to rely on logical replication in the general case of arbitrary SQL access. Because we control the API, we can ensure that updates and deletes are done in transactions of reasonable size, which can be rate limited in order to protect the system from overload.
Xata offers general purpose storage for file attachments through the file column type. By integrating file support in the database, Xata aims to simplify the management of large binary content, by exposing it under the same API, same security model, same SDK. At the same time, the queries, filters, summaries, aggregations available can now be used on files metadata. The metadata (file name, media type, tags) is also indexed for search so it can be included in search results.
In order to offer both database benefits like queries and CRUD and storage service benefits like - high capacity, high throughput, high concurrency, regional caching - Xata stores the files' metadata in PostgreSQL and the actual binary content in a dedicated cloud storage service.
Direct access URLs are generated and offered through the database API. When using these URLs, the content is served directly from the storage service, therefore enabling greater throughput and concurrency compared to relational data access. The content accessed through the direct access URLs is also cached regionally. Xata integrates with a CDN service with a wide geographical distribution to offer content caching as close as possible to the client application. Xata integrates with an image transformation engine, providing a set of transformations which can be applied on-the-fly and cached.
In all cache systems, the main challenge lies in cache invalidation. This means achieving fast cache access performance while effectively handling content updates and preventing the delivery of outdated information.
Xata implements a cache-invalidation-free approach to optimize file content delivery. The files are treated as dynamic content, similar to the data stored in the database. To ensure efficient handling of updates and prevent stale entries, it is recommended that clients dynamically fetch access URLs directly from the database, rather than relying on static resources. Whenever a file undergoes an update, new URLs are automatically generated and subsequently recognized by the client application during the next database read.
By generating fresh URLs after each update, Xata effectively eliminates the possibility of serving outdated entries, regardless of the presence of intermediate caches or proxies between the client and the storage service. This approach eliminates the need for cache time-to-live (TTL) or dealing with cache invalidation latency, resulting in improved performance for the client application.
When the client application retrieves the URL from the database, it is guaranteed to access the most up-to-date version of the file available. This ensures seamless delivery of the latest file content without the risk of serving stale data.
Xata exposes its functionality over a RESTful-like API. A sample query with a filter looks like this:
// POST /db/tutorial:main/tables/Users/query
{
"filter": {
"zipcode": 12345
},
"columns": ["name", "street_name, zipcode, city, country"]
}A simple free-text-search request looks something like this:
// POST /db/tutorial:main/tables/Users/search
{
"query": "keanu",
"fuzziness": 1,
"filter": {
"zipcode": 12345
}
}An aggregation request looks something similar to the follwing:
// POST /db/tutorial:main/tables/Users/aggregate
{
"aggs": {
"NewYorkUsers": {
"count": {
"filter": {
"city": "New York"
}
}
},
"citiesCount": {
"uniqueCount": {
"column": "city"
}
}
}
}The /query and /summarize API endpoints are served from the transactional store (PostgreSQL) and you can choose if you want them to be strongly consistent or to use a read replica. The /search and /aggregate API endpoints are served from the search and analytics engine (Elasticsearch) and offer only eventual consistency.
As you can see in the above examples, the filtering syntax is the same across the different types of stores, meaning that it’s easy to move queries from one to another.
While we expect most users to use our high-level SDK clients, which make development easier, the REST API is meant to be also easy to understand and use directly. Because it is using JSON, it is more verbose than SQL, but on the other hand, it makes it easier to use with functionality that doesn’t cleanly map into SQL, like free-text-search, complex aggregations, etc.
At the moment, the Xata service doesn’t offer direct access to the PostgreSQL and Elasticsearch instances using their native protocols. The reasons for this might become more clear after reading the following sections, but in short: it allows us to control the underlying schema and what type of queries are possible, and therefore we can ultimately offer our users a new and safer developer experience. For the future, we do have plans to offer SQL support while still maintaining the advantages of mediating access to the underlying stores.
Xata has official SDKs for TypeScript/Javascript and Python, and the REST API is meant to be used with ease from any programming language. Having said that, the TypeScript SDK is by far the most advanced SDK that we have.
It uses code generation to generate the models from your schema, so using it is similar to using an ORM.
For example, consider the following command:
const user = await xata.db.users.filter('email', 'foo@example.com').getFirst();The command gets the first record from the users table that matches the filter. The user variable has the type UsersRecord, which is automatically generated and which has all the columns defined as properties, plus methods like update() and delete() to work with it. This means that you get type safety out of the box and the editor or IDE will be able to auto-complete table and column names, making writing code easy and fast.
To update the record in the DB you can do the following:
await user.update({
name: 'John Smith Jr.'
});and to delete it you can do:
await user.delete();In usage, using the Xata TypeScript SDK is similar to using a Typescript ORM, for example, Prisma. It is generally easy to port applications that use Xata to Prisma and the other way around, because while not 100% compatible, the two are fairly similar.
Under the hood, however, the Xata SDK is implemented a bit differently and makes use of recent TypeScript additions to generate the types at run-time. It also has a somewhat simpler problem to solve, because it only needs to talk with the Xata API, not generate SQL. The result of this is that the Xata SDK is very lightweight and has zero dependencies, so it can be used in many JavaScript runtimes including Node.js, Cloudflare Workers, Deno, Electron, etc.
Xata is committed to protecting the security and ensuring the availability of user data. To do so, we implement appropriate technical measures and internal organization policies to protect from unauthorized access, data leak or loss.
As part of our commitment to securing data access and storage, Xata encrypts user data content:
- during network transit with Transport Layer Security
- at rest with storage encryption provided by our underlying infrastructure providers
The same level of security standard applies to internal backups, logs and traces which do not expose plain text data content to third parties.
For disaster recovery and change control purposes, Xata performs frequent backups of user data which is retained only as required and while it continues to have a legitimate purpose for delivering our services to the user.
At Xata we are taking hard data problems, solve them using the industry's best practices, and then offer them to you in the most easy-to-use way possible.
Zero-downtime migrations are an example of this: difficult under the hood, but a familiar-looking pull request with a diff in our UI. Change Data Capture is another example: generally difficult to get right, but inside Xata your data is simply replicated to the search engine, with zero configuration.
Our design principles are:
- Use proven technology, best-in-class for a particular data problem. This is the reason we use PostgreSQL for the main data store and Elasticsearch for search and analytics. For edge functions, we rely on Cloudflare Workers, which has a wide and reliable network. Because we use proven technology, the resulting service is reliable and your data is safe.
- Build for vertical integration for a smooth developer experience. Besides the backend service, we put a lot of effort into our admin UI and SDKs in multiple languages. They work together without any friction.
- Cloud-only and serverless. Operating and monitoring databases is hard, especially when dealing with multiple of them. We are taking as much load off your shoulders as we can. This includes high availability, maintaining replicas, global distributions, etc. This blog post goes into detail on what we mean when we talk about serverless databases.
- Make the complex simple. We’re leveraging things like the UI, rich data types, and high-level SDK in order to to make Xata the easiest database to use. At the same time, we’re not sacrificing power, and our functionality goes deep in aspects like search and analytics.
Xata is a relatively new service and we have a lot of ideas for improving it. For example, we plan to add more data stores and more ways to take advantage of the existing data stores. But you can expect us to follow the principles above.